
Ứng dụng Machine Learning để phân tích thay đổi trong phát biểu của quan chức Fed như thế nào?

Nguyễn Phương Anh
Junior Analyst
Tháng 3/2022, Cục Dự trữ Liên bang Mỹ đã bắt đầu khởi động lại chu kỳ thắt chặt chính sách lần đầu tiên sau 3 năm. Kể từ đó, hoạt động đầu tư mua và nắm giữ các loại tài sản đều có tỷ suất sinh lời rất thấp thậm chí lỗ vốn. Trong khi mối đó, mối tương quan giữa trái phiếu và cổ phiếu ngày một gia tăng, khiến cho tài sản như trái phiếu không còn là nơi trú ẩn cho tâm lý đầu tư nữa.

Khi chiến lược đa dạng hoá các loại tài sản đầu tư tạm thời không quá cần thiết, nhà đầu tư dần tập trung vào việc cố gắng có góc nhìn khách quan và nắm được triển vọng từ Uỷ ban Thị trường mở Liên bang (FOMC).
Và đây là lúc máy học (machine learning) và xử lý ngôn ngữ tự nhiên (natural language processing) bắt đầu nhập cuộc. Trong bài viết này, ta sẽ phân tích cách phân loại các từ vựng thể hiện quan điểm của các quan chức dựa trên nền tảng lý thuyết của Loughran-McDonald (Loughran-McDonald sentiment word list - từ đây gọi tắt là danh sách Loughran-McDonald - ND) và các kỹ thuật máy học như BERT và XLnet trong quá trình xử lý ngôn ngữ từ các biên bản báo cáo của FOMC để xem liệu chúng có thể dự đoán được những thay đổi trong lãi suất quỹ liên bang hay không. Từ đó, ta sẽ kiểm tra liệu kết quả có mối tương quan ra sao với hoạt động của thị trường chứng khoán.
** Chú thích từ người dịch: Phân tích quan điểm (sentiment analysis) là một kỹ thuật xử lý ngôn ngữ tự nhiên giúp ta xác định quan điểm thể hiện trong một văn bản nhất định. Một mô hình phân tích quan điểm người dùng có thể giúp dự đoán thái độ trong văn bản là tích cực, tiêu cực hay trung lập bằng cách trích xuất ý nghĩa từ ngôn ngữ tự nhiên và gán nó với nhãn phù hợp. Tham khảo: vinbigdata.com
Danh sách Loughran-McDonald
Trước khi chấm điểm tâm lý thị trường (sentiment score), ta cần xây dựng các đám mây từ vựng (word cloud) để trực quan hoá tần suất xuất hiện, hay tầm quan trọng của một số từ cụ thể trong báo cáo FOMC.
Ví dụ về Word Cloud của biên bản FOMC Statement tháng 3/2017

Ví dụ về Word Cloud của biên bản FOMC Statement tháng 7/2019

Mặc dù Fed đã tăng lãi suất quỹ liên bang vào tháng 3/2017 và giảm lãi suất vào tháng 7/2019, word cloud của hai báo cáo tương ứng các năm trông vẫn na ná nhau. Ta có thể giải thích rằng các tuyên bố của FOMC thường chứa nhiều từ mang tính trung lập, và không hàm chứa nhiều ý nghĩa để giúp ta dự đoán triển vọng của FOMC. Word cloud không giúp ta có thêm nhiều từ khoá hữu ích, đặc biệt khi chúng chưa thể “lọc” ra các “từ ngữ gây nhiễu". Tuy nhiên, ta có thể kỳ vọng nhiều hơn vào các phân tích định lượng.
Danh sách Loughran-McDonald thu thập dữ liệu từ các tài liệu 10-K, bản ghi từ các báo cáo kết quả kinh doanh (earnings call), và một số dạng văn bản (text) khác, sau đó sẽ phân tích chúng qua việc phân loại các từ ngữ xuất hiện vào các nhóm khác nhau. Tại đây, ta có thể phân loại theo thái độ, quan điểm như: Tiêu cực, tích cực, mơ hồ, hàm chứa rủi ro liên quan tới pháp luật, các từ khuyết thiếu thể hiện quan điểm rõ ràng (phải, chắc,...) hoặc không rõ ràng (có thể, hình như,...), hay các từ hàm ý cấm đoán/hạn chế. Trong bài viết này, ta sẽ áp dụng kỹ thuật phân tích này lên các tuyên bố của FOMC, chỉ định và sắp xếp thành các nhóm từ ngữ như cứng rắn (hawkish) hay mềm mỏng (dovish), đồng thời lọc ra những từ ngữ không cần thiết như ngày tháng, số trang, thành viên bỏ phiếu và những phần giải thích về việc thực hiện chính sách tiền tệ. Sau đó, ta sẽ tính toán điểm tâm lý hiện tại bằng công thức sau:
Điểm thái độ = (Từ tích cực – Từ tiêu cực) / (Từ tích cực + Từ tiêu cực)
Công bố văn kiện của FOMC: Điểm tâm lý theo lý thuyết của Loughran-McDonald
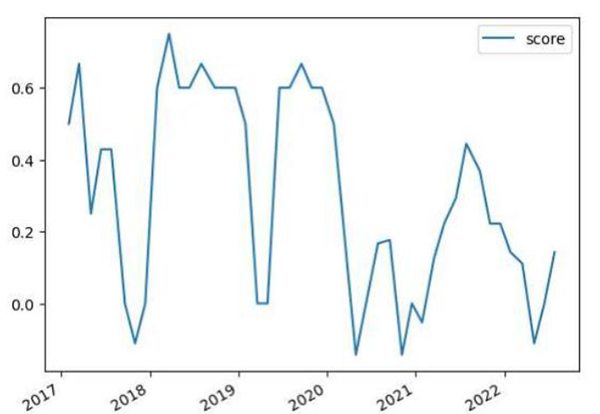
Như ta thấy trên biểu đồ, các tuyên bố của FOMC ngày càng có xu hướng tích cực (hawkish) hơn trong tháng 3/2021 và đạt đỉnh vào tháng 7/2021. Sau khi lắng xuống trong 12 tháng tiếp theo, xu hướng tích cực lại tăng đến đỉnh điểm vào tháng 7/2022. Mặc dù những chuyển biến này có thể được giải thích từ sự phục hồi sau đại dịch Covid-19, chúng cũng phản ánh thái độ hawkish ngày càng tăng của FOMC trước tình trạng lạmp phát gia tăng trong năm vừa rồi.
Những biến động lớn thể hiện trên biểu đồ cũng cho ta thấy một thiếu sót cố hữu trong kỹ thuật phân tích Loughran-McDonald: Điểm tâm lý chỉ đánh giá các từ ngữ thay vì đánh giá các câu/cụm từ. Ví dụ: Trong câu “Tỷ lệ thất nghiệp giảm”, cả hai từ đều được phân loại tiêu cực, mặc dù ta có thể thấy rõ hàm ý tích cực khi đọc đầy đủ cả câu.
Để khắc phục điểm yếu từ kỹ thuật này, ta sẽ huấn luyện các mô hình BERT và XLNet để phân tích FOMC theo từng câu một.
Kỹ thuật phân tích BERT và XLNet
BERT là một mô hình máy học, thực hiện encoder nhằm tạo ra các vector đại diện cho từ ngữ trong văn bản thông qua ngữ cảnh 2 chiều thay vì 1 chiều để cho ra kết quả tinh chỉnh (fine-tuning) tốt hơn. Với khả năng encoder 2 chiều, BERT thể hiện khả năng hoạt động xuất sắc vượt qua OpenAI GPT - một mô hình encoder 1 chiều.
XLNet là một phương pháp huấn luyện trước (pretraining) tự động hồi quy tổng quát (generalized autoregressive) có chung đặc tính encoder 2 chiều, nhưng không sử dụng mô hình ngôn ngữ bị ẩn (masked-language modeling - MLM), cung cấp cho BERT một câu hoàn chỉnh và tối ưu hoá các trọng số trong BERT để có đầu ra (output) là các câu tương ứng với chiều còn lại. Trước khi chúng ta đưa cho BERT một câu văn ở đầu vào (input), ta sẽ cần ẩn một số tokens trong MLM. Với XLNet, ta sẽ không cần bước ẩn tokens nữa, giúp cho phương pháp này trở thành phiên bản cải tiến từ BERT.
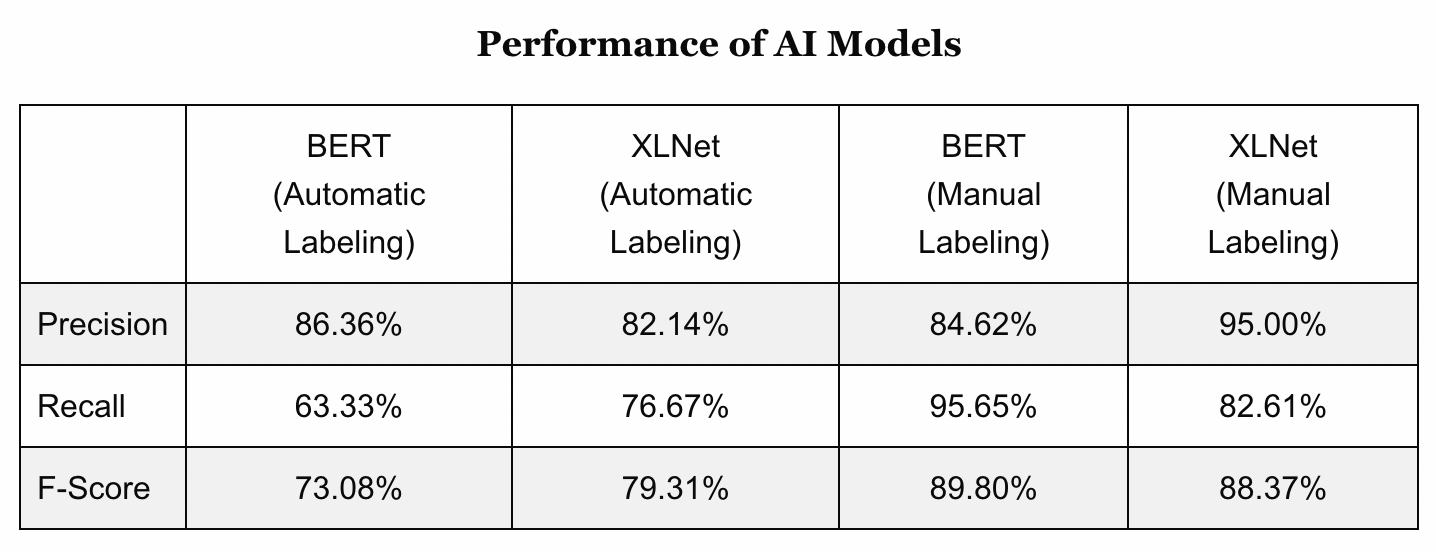
Để huấn luyện hai mô hình này, ta sẽ chia các câu lệnh FOMC thành các tập dữ liệu: (1) Tập huấn luyện (training datasets), (2) tập thử nghiệm (test datasets), và (3) tập ngoài mẫu (out-of-sample datasets). Ta sẽ trích xuất các tập training và test trong giai đoạn từ tháng 2/2017 cho tới tháng 12/2020, và tập out-of-sample sẽ lấy dữ liệu trong giai đoạn từ tháng 6/2021 tới tháng 7/2022. Sau đó, ta sẽ áp dụng hai kỹ thuật gán nhãn (labeling) khác nhau: thủ công và tự động. Khi sử dụng phương pháp gán nhãn tự động, ta sẽ gán cho các câu với giá trị 1, 0, hoặc bỏ trống, dựa trên việc câu văn thể hiện sự tăng, sự giảm, hay không thay đổi trong lãi suất điều hành của Fed. Khi gán nhãn thủ công, ta phân loại các câu với giá trị 1, 0, hoặc bỏ trống, tuỳ thuộc vào việc chúng thể hiện thái độ hawkish, dovish, hay trung tính.
Sau đó, ta sẽ sử dụng công thức sau để tính điểm tâm lý:
Điểm tâm lý = (Câu tích cực – Câu tiêu cực) / (Câu tích cực + Câu tiêu cực)
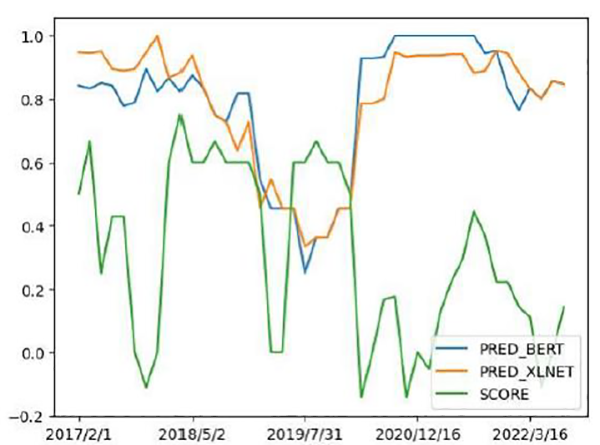
Dự báo điểm tâm lý qua dữ liệu được gán nhãn tự động
Dự báo điểm thái độ bằng dữ liệu được gán nhãn thủ công
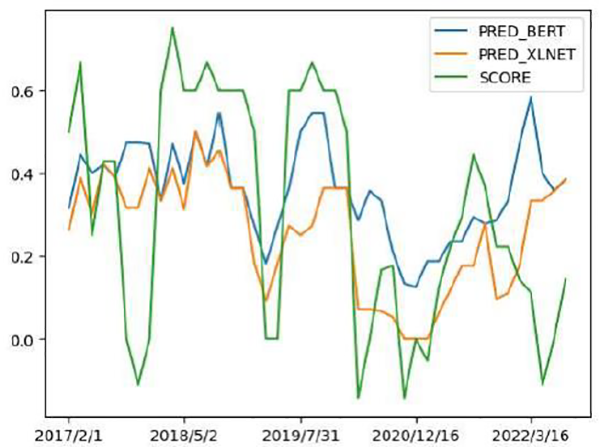
Hai biểu đồ trên cho ta thấy việc gán nhãn thủ công nắm rõ hơn sự thay đổi gần đây trong quan điểm của FOMC. Mỗi tuyên bố đều có các câu hàm chứa thái độ hawkish (hoặc dovish) mặc FOMC cuối cùng đã đưa ra quyết định hạ (hoặc tăng) lãi suất quỹ liên bang. Ta có thể thấy việc gán nhãn từng câu sẽ giúp ta huấn luyện các mô hình máy học tốt hơn.
Khi phần lớn chúng ta khó có thể quan sát cơ chế hoạt động của các mô hình máy học hay trí tuệ nhân tạo (AI), việc diễn giải kết quả từ các mô hình này trở nên vô cùng quan trọng. Một trong những phương pháp có thể kể đến là phương pháp LIME (Local Interpretable Model-Agnostic Explanations). Phương pháp này áp dụng một mô hình đơn giản để giải thích cho một mô hình phức tạp hơn thế. Ta có thể xem hai biểu đồ bên dưới để thấy cách XLNet (sử dụng dữ liệu được gán nhãn thủ công) diễn giải các câu từ tuyên bố của FOMC, nhận diện được câu đầu tiên thể hiện thái độ tích cực dựa trên sự phát triển của thị trường lao động và quy mô vừa phải của các hoạt động kinh tế mở rộng, và câu thứ hai thể hiện thái độ tiêu cực khi giá tiêu dùng giảm và lạm phát ở mức dưới 2%. Đánh giá của mô hình về cả hoạt động kinh tế và áp lực từ lạm phát nhìn chung là hợp lý.

Lời kết
Bằng cách trích xuất các câu từ các tuyên bố và đánh giá thái độ thể hiện trong các văn bản, các kỹ thuật học máy giúp ta hiểu rõ hơn về quan điểm chính sách của FOMC, hé lộ tiềm năng có thể giúp ta diễn giải và hiểu hơn về các hoạt động truyền thông từ ngân hàng trung ương.
Vậy nhưng, liệu ta có thể nhận thấy một mối liên hệ rõ rệt giữa những thay đổi trong thái độ từ các tuyên bố của FOMC và lợi nhuận của thị trường chứng khoán Mỹ? Biểu đồ bên dưới cho ta thấy lợi nhuận tích luỹ của Chỉ số Trung bình Công nghiệp Dow Jones (DJIA) và NASDAQ Composite (IXIC) cùng với điểm độ nhạy FOMC. Qua việc đánh giá mối tương quan, nhận diện các lỗi sai, theo dõi lợi nhuận vượt mức và biến động vượt mức, ta có thể phát hiện những thay đổi về tỷ số lợi nhuận của cổ phiếu được đo trên trục tung.
Lợi nhuận của cổ phiếu và Điểm độ nhạy của tuyên bố FOMC

Kết quả cho thấy, đúng như mong đợi, điểm thái độ giúp ta nhận diện những thay đổi trong chế độ, khi những thay đổi về chế độ thị trường chứng khoán và những thay đổi đột ngột về điểm thái độ FOMC xảy ra gần như cùng thời điểm. Ta có thể thấy NASDAQ thậm chí có thể phản ứng nhanh hơn cả điểm thái độ của FOMC.
Bài viết này là một gợi ý giúp mọi người quan tâm nhiều hơn tới tiềm năng to lớn của các kỹ thuật máy học ứng dụng trong việc quản lý đầu tư trong tương lai. Tất nhiên, trong các bước phân tích cuối cùng, sự kết hợp giữa các kỹ thuật hiện đại và óc phán đoán của chính chúng ta sẽ đem lại giá trị tối ưu nhất.
CFA Institute







")
")
")
")
")



